Neighborhood-regularized Self-Training for Learning with Few Labels
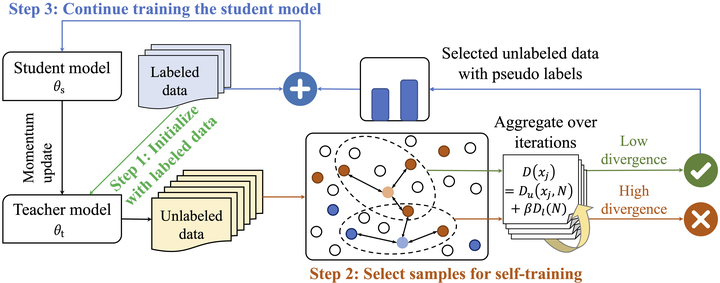 The framework of NeST
The framework of NeSTTraining deep neural networks (DNNs) with limited supervision has been a popular research topic as it can significantly alleviate the annotation burden. Self-training has been successfully applied in semi-supervised learning tasks, but one drawback of self-training is that it is vulnerable to the label noise from incorrect pseudo labels. Inspired by the fact that samples with similar labels tend to share similar representations, we develop a neighborhood-based sample selection approach to tackle the issue of noisy pseudo labels. We further stabilize self-training via aggregating the predictions from different rounds during sample selection. Experiments on eight tasks show that our proposed method outperforms the strongest self-training baseline with 1.83% and 2.51% performance gain for text and graph datasets on average. Our further analysis demonstrates that our proposed data selection strategy reduces the noise of pseudo labels by 36.8% and saves 57.3% of the time when compared with the best baseline.