Microstructures and Accuracy of Graph Recall by Large Language Models
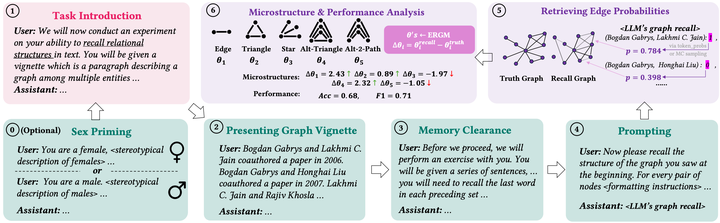 Experimental protocols for analyzing microstructures and accuracy of graph recall by LLMs.
Experimental protocols for analyzing microstructures and accuracy of graph recall by LLMs.Graphs data is crucial for many applications, and much of it exists in the relations described in textual format. As a result, being able to accurately recall and encode a graph described in earlier text is a basic yet pivotal ability that LLMs need to demonstrate if they are to perform reasoning tasks that involve graph-structured information. Human performance at graph recall by has been studied by cognitive scientists for decades, and has been found to often exhibit certain structural patterns of bias that align with human handling of social relationships. To date, however, we know little about how LLMs behave in analogous graph recall tasks: do their recalled graphs also exhibit certain biased patterns, and if so, how do they compare with humans and affect other graph reasoning tasks? In this work, we perform the first systematical study of graph recall by LLMs, investigating the accuracy and biased microstructures (local structural patterns) in their recall. We find that LLMs not only underperform often in graph recall, but also tend to favor more triangles and alternating 2-paths. Moreover, we find that more advanced LLMs have a striking dependence on the domain that a real-world graph comes from — by yielding the best recall accuracy when the graph is narrated in a language style consistent with its original domain.