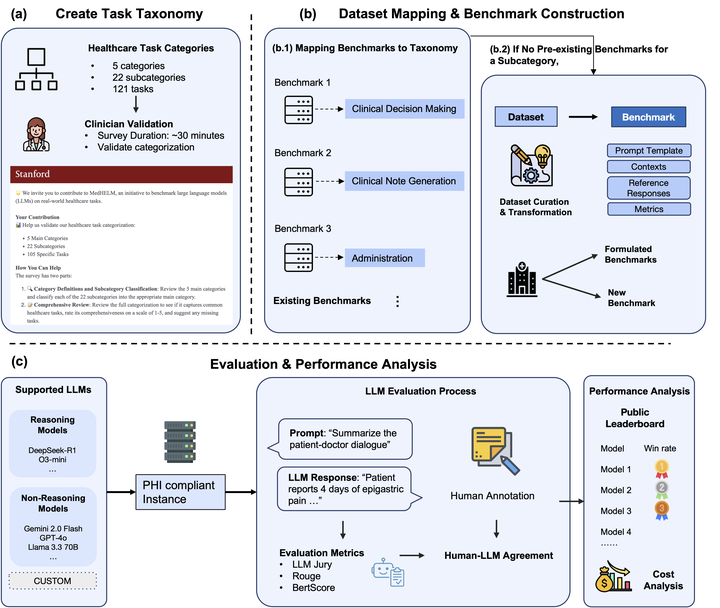
 Overview of MedHELM. MedHELM provides a clinician-validated taxonomy of 121 medical tasks, a 37-benchmark evaluation suite, and a robust LLM-jury methodology for assessing real-world performance of LLMs in healthcare.
Overview of MedHELM. MedHELM provides a clinician-validated taxonomy of 121 medical tasks, a 37-benchmark evaluation suite, and a robust LLM-jury methodology for assessing real-world performance of LLMs in healthcare.Large language models (LLMs) achieve near-perfect scores on medical licensing exams, yet these benchmarks fail to capture the complexity of real-world clinical practice. MedHELM addresses this gap by introducing a clinician-validated taxonomy of five categories, 22 subcategories, and 121 medical tasks; a suite of 37 benchmarks (including real-world EHR datasets); and an improved evaluation methodology leveraging an LLM-jury approach.
Our evaluation of nine frontier LLMs shows significant variation in performance: reasoning models such as DeepSeek R1 and o3-mini achieve the highest win-rates (66% and 64%), while existing automated metrics (e.g., ROUGE, BERTScore) underperform compared with clinician-aligned LLM-judging (ICC = 0.47). Models perform best on Clinical Note Generation and Patient Communication, moderately on Medical Research Assistance and Clinical Decision Support, and worst on Administration & Workflow tasks.
MedHELM establishes a standardized, extensible, and clinically grounded framework for benchmarking LLMs, offering critical insights for healthcare deployment and future medical AI development.