
I am a Senior Research Scientist at Google, focusing on large language models and agentic AI systems. Previously, I was at Amazon Rufus (Foundation Models Team), where I worked on large-scale LLM post-training and alignment for Amazon's Shopping LLM. My research spans reinforcement learning, instruction fine-tuning, synthetic data generation, and evaluation methods for improving LLM reasoning, reliability, and controllability.
Before that, I was a Postdoctoral Researcher at Stanford University, advised by Prof. Nigam H. Shah and Prof. Sanmi Koyejo. I received my Ph.D. in Computer Science from Emory University, advised by Prof. Carl Yang, and my B.Eng. in Software Engineering from Tongji University as Valedictorian (GPA 4.9/5.0, Rank 1/164) with 3x National Scholarships. During undergrad, I worked with Prof. Tianwei Yu on machine learning research and interned at the Perk Lab with Prof. Gabor Fichtinger at Queen's University.
Education
-
 Stanford UniversityPostdoctoral Researcher2024 - 2025
Stanford UniversityPostdoctoral Researcher2024 - 2025 -
 Emory UniversityPh.D. in Computer Science2019 - 2024
Emory UniversityPh.D. in Computer Science2019 - 2024 -
 Tongji UniversityB.Eng. in Software Engineering2015 - 2019
Tongji UniversityB.Eng. in Software Engineering2015 - 2019
Experience
-
 GoogleSenior Research Scientist2026 - Present
GoogleSenior Research Scientist2026 - Present -
 Amazon Rufus (Foundation Models Team)Applied Scientist2025 - 2026
Amazon Rufus (Foundation Models Team)Applied Scientist2025 - 2026 -
 Microsoft ResearchResearch InternSummer 2023
Microsoft ResearchResearch InternSummer 2023 -
AmazonApplied Scientist InternSummer 2022
Honors & Awards
-
2023
-
NeurIPS AI4Science Scholarship Award2022
-
Valedictorian, School of Software Engineering, Tongji University2019
News
Selected Publications (view all )
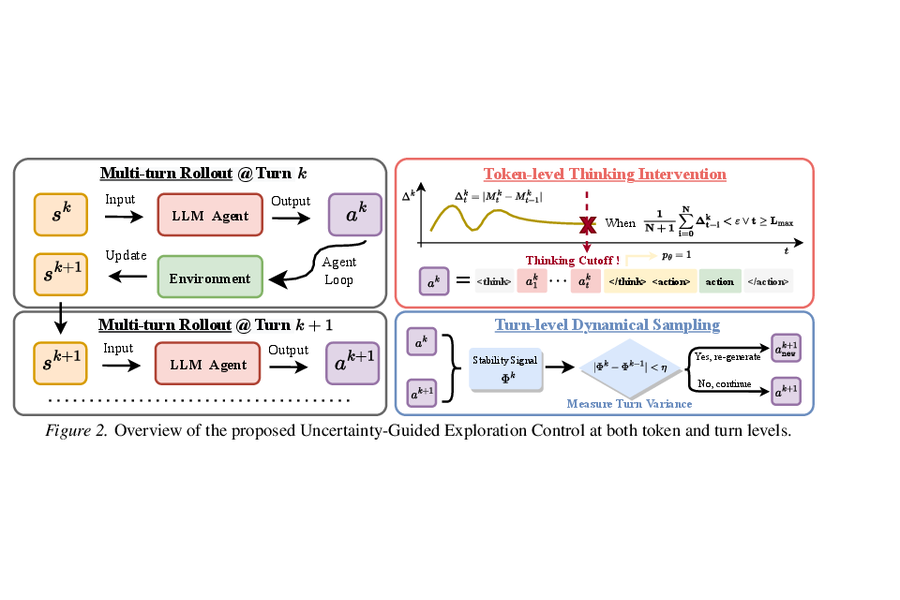
T²PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
Haixin Wang, Hejie Cui#, Chenwei Zhang, Xin Liu, Shuowei Jin, Shijie Geng, Xinyang Zhang, Nasser Zalmout, Zhenyu Shi, Yizhou Sun (# corresponding author)
The International Conference on Machine Learning (ICML) 2026 Spotlight
Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse.
T²PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
Haixin Wang, Hejie Cui#, Chenwei Zhang, Xin Liu, Shuowei Jin, Shijie Geng, Xinyang Zhang, Nasser Zalmout, Zhenyu Shi, Yizhou Sun (# corresponding author)
The International Conference on Machine Learning (ICML) 2026 Spotlight
Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse.

HeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Weiqi Wang, Xin Liu, Binxuan Huang, Hejie Cui, Rongzhi Zhang, Changlong Yu, Shuowei Jin, Jingfeng Yang, Qingyu Yin, Zhengyang Wang, Zheng Li, Yifan Gao, Priyanka Nigam, Bing Yin, Lihong Li, Yangqiu Song
The Conference on Language Modeling (COLM) 2026
RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. We introduce HeaPA, a query-side RLVR framework that combines difficulty-aware heap-based frontier sampling with on-policy query augmentation to improve math reasoning efficiency and accuracy.
HeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Weiqi Wang, Xin Liu, Binxuan Huang, Hejie Cui, Rongzhi Zhang, Changlong Yu, Shuowei Jin, Jingfeng Yang, Qingyu Yin, Zhengyang Wang, Zheng Li, Yifan Gao, Priyanka Nigam, Bing Yin, Lihong Li, Yangqiu Song
The Conference on Language Modeling (COLM) 2026
RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. We introduce HeaPA, a query-side RLVR framework that combines difficulty-aware heap-based frontier sampling with on-policy query augmentation to improve math reasoning efficiency and accuracy.
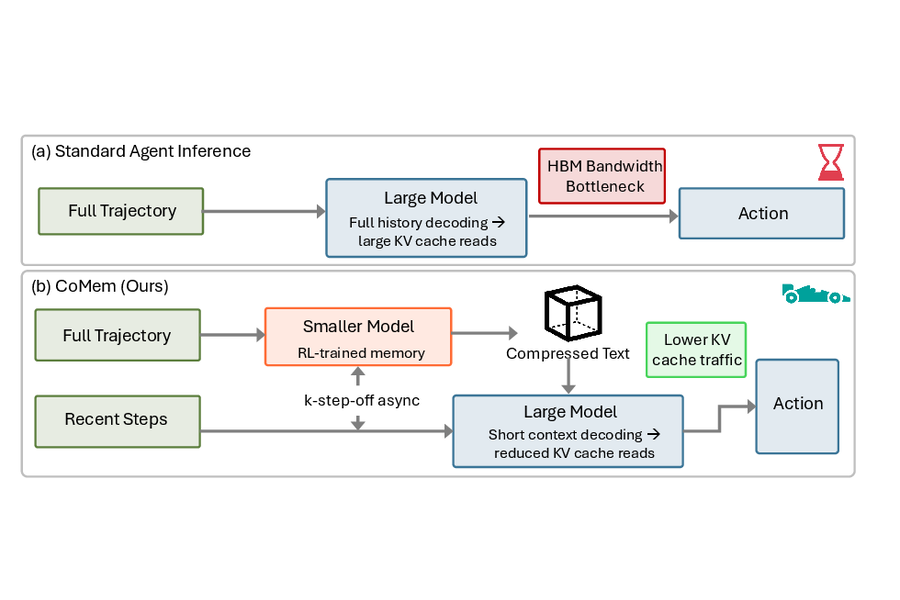
CoMem: Context Management with A Decoupled Long-Context Model
Yuwei Zhang, Chengyu Dong, Shuowei Jin, Changlong Yu, Hejie Cui, Hongye Jin, Xinyang Zhang, Hamed Bonab, Colin Lockard, Jianshu Chen, Zhenyu Shi, Jingbo Shang, Xian Li, Bing Yin
The International Conference on Machine Learning (ICML) 2026
Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment.
CoMem: Context Management with A Decoupled Long-Context Model
Yuwei Zhang, Chengyu Dong, Shuowei Jin, Changlong Yu, Hejie Cui, Hongye Jin, Xinyang Zhang, Hamed Bonab, Colin Lockard, Jianshu Chen, Zhenyu Shi, Jingbo Shang, Xian Li, Bing Yin
The International Conference on Machine Learning (ICML) 2026
Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment.
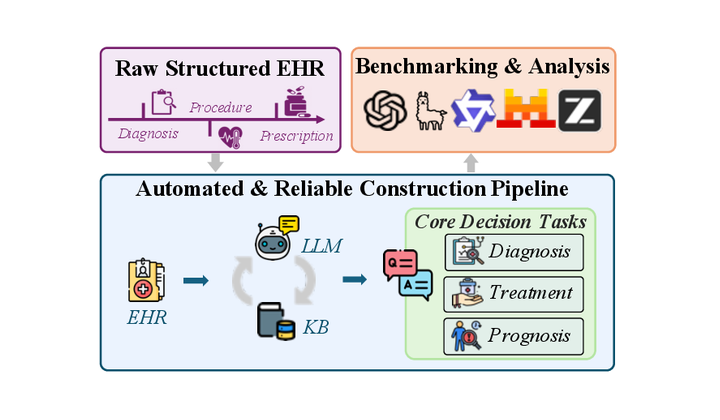
EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
Yuzhang Xie, Keqi Han, Yunpeng Xiao, Hejie Cui, Guanchen Wu, Ziyang Zhang, Kai Shu, Jiaying Lu, Xiao Hu, Carl Yang
The ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Datasets and Benchmarks Track 2026 Oral
Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. EHRBench is an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. It constructs nearly 1M QA items spanning diagnosis, treatment, and prognosis, and benchmarks more than 30 representative LLMs to reveal actionable gaps toward clinically reliable LLM systems.
EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
Yuzhang Xie, Keqi Han, Yunpeng Xiao, Hejie Cui, Guanchen Wu, Ziyang Zhang, Kai Shu, Jiaying Lu, Xiao Hu, Carl Yang
The ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Datasets and Benchmarks Track 2026 Oral
Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. EHRBench is an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. It constructs nearly 1M QA items spanning diagnosis, treatment, and prognosis, and benchmarks more than 30 representative LLMs to reveal actionable gaps toward clinically reliable LLM systems.
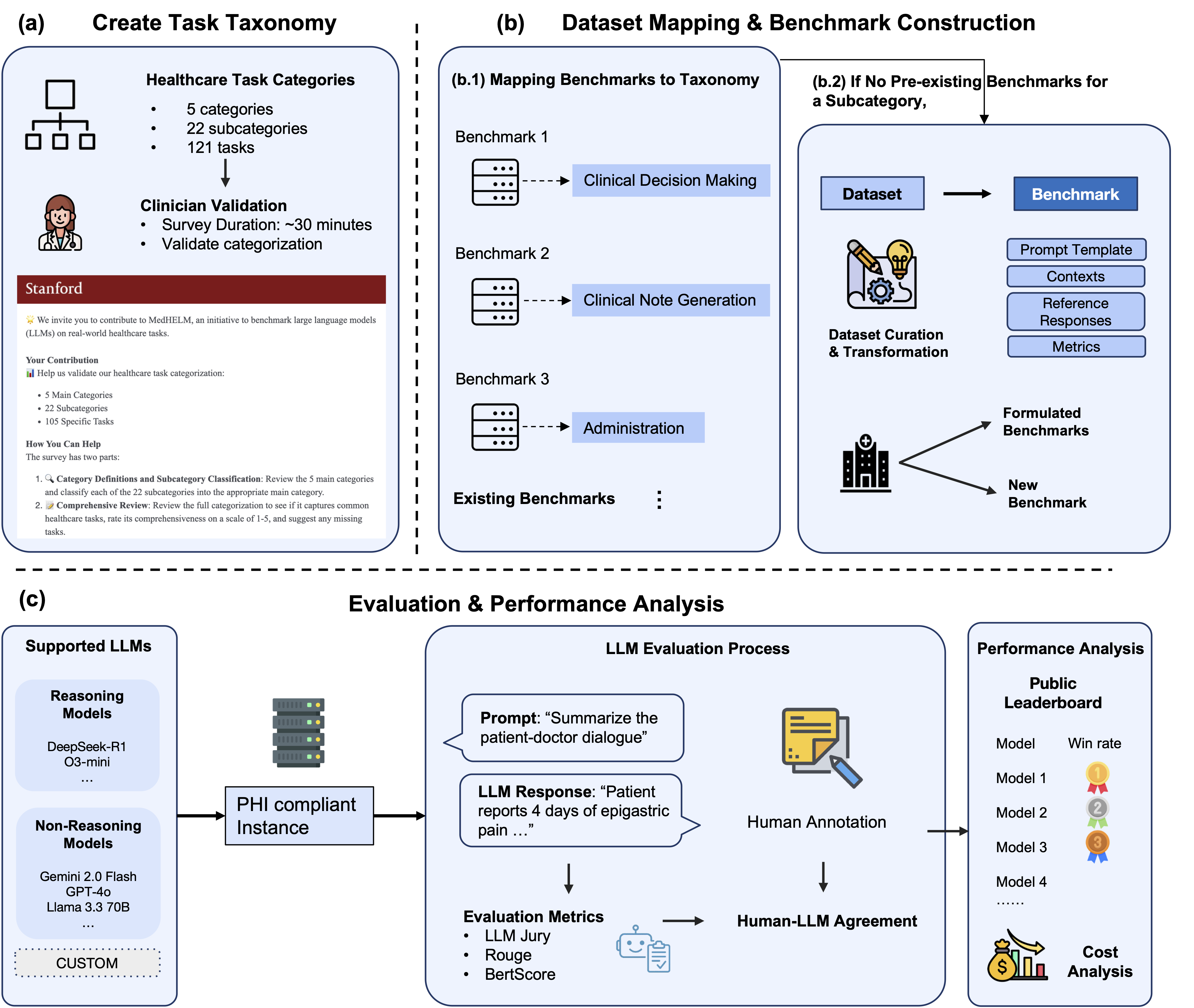
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
Suhana Bedi*, Hejie Cui*, Miguel Fuentes*, Alyssa Unell*, Michael Wornow, Juan M. Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, Hao Qiu, Shrey Jain, Leonardo Schettini, Mehr Kashyap, Jason Alan Fries, Akshay Swaminathan, Philip Chung, Fateme Nateghi Haredasht, Ivan Lopez, Asad Aali, Gabriel Tse, Ashwin Nayak, Shivam Vedak, Sneha S. Jain, Birju Patel, Oluseyi Fayanju, Shreya Shah, Ethan Goh, Dong-han Yao, Brian Soetikno, Eduardo Reis, Sergios Gatidis, Vasu Divi, Robson Capasso, Rachna Saralkar, Chia-Chun Chiang, Jenelle Jindal, Tho Pham, Faraz Ghoddusi, Steven Lin, Albert S. Chiou, Christy Hong, Mohana Roy, Michael F. Gensheimer, Hinesh Patel, Kevin Schulman, Dev Dash, Danton Char, Lance Downing, Francois Grolleau, Kameron Black, Bethel Mieso, Aydin Zahedivash, Wen-wai Yim, Harshita Sharma, Tony Lee, Hannah Kirsch, Jennifer Lee, Nerissa Ambers, Carlene Lugtu, Aditya Sharma, Bilal Mawji, Alex Alekseyev, Vicky Zhou, Vikas Kakkar, Jarrod Helzer, Anurang Revri, Yair Bannett, Roxana Daneshjou, Jonathan Chen, Emily Alsentzer, Keith Morse, Nirmal Ravi, Nima Aghaeepour, Vanessa Kennedy, Akshay Chaudhari, Thomas Wang, Sanmi Koyejo, Matthew P. Lungren, Eric Horvitz, Percy Liang, Michael A. Pfeffer, Nigam H. Shah (* equal contribution)
Nature Medicine (5-Year Impact Factor: 52.4) 2026
Large language models (LLMs) achieve near-perfect scores on medical licensing exams, yet these benchmarks fail to capture the complexity of real-world clinical practice.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
Suhana Bedi*, Hejie Cui*, Miguel Fuentes*, Alyssa Unell*, Michael Wornow, Juan M. Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, Hao Qiu, Shrey Jain, Leonardo Schettini, Mehr Kashyap, Jason Alan Fries, Akshay Swaminathan, Philip Chung, Fateme Nateghi Haredasht, Ivan Lopez, Asad Aali, Gabriel Tse, Ashwin Nayak, Shivam Vedak, Sneha S. Jain, Birju Patel, Oluseyi Fayanju, Shreya Shah, Ethan Goh, Dong-han Yao, Brian Soetikno, Eduardo Reis, Sergios Gatidis, Vasu Divi, Robson Capasso, Rachna Saralkar, Chia-Chun Chiang, Jenelle Jindal, Tho Pham, Faraz Ghoddusi, Steven Lin, Albert S. Chiou, Christy Hong, Mohana Roy, Michael F. Gensheimer, Hinesh Patel, Kevin Schulman, Dev Dash, Danton Char, Lance Downing, Francois Grolleau, Kameron Black, Bethel Mieso, Aydin Zahedivash, Wen-wai Yim, Harshita Sharma, Tony Lee, Hannah Kirsch, Jennifer Lee, Nerissa Ambers, Carlene Lugtu, Aditya Sharma, Bilal Mawji, Alex Alekseyev, Vicky Zhou, Vikas Kakkar, Jarrod Helzer, Anurang Revri, Yair Bannett, Roxana Daneshjou, Jonathan Chen, Emily Alsentzer, Keith Morse, Nirmal Ravi, Nima Aghaeepour, Vanessa Kennedy, Akshay Chaudhari, Thomas Wang, Sanmi Koyejo, Matthew P. Lungren, Eric Horvitz, Percy Liang, Michael A. Pfeffer, Nigam H. Shah (* equal contribution)
Nature Medicine (5-Year Impact Factor: 52.4) 2026
Large language models (LLMs) achieve near-perfect scores on medical licensing exams, yet these benchmarks fail to capture the complexity of real-world clinical practice.
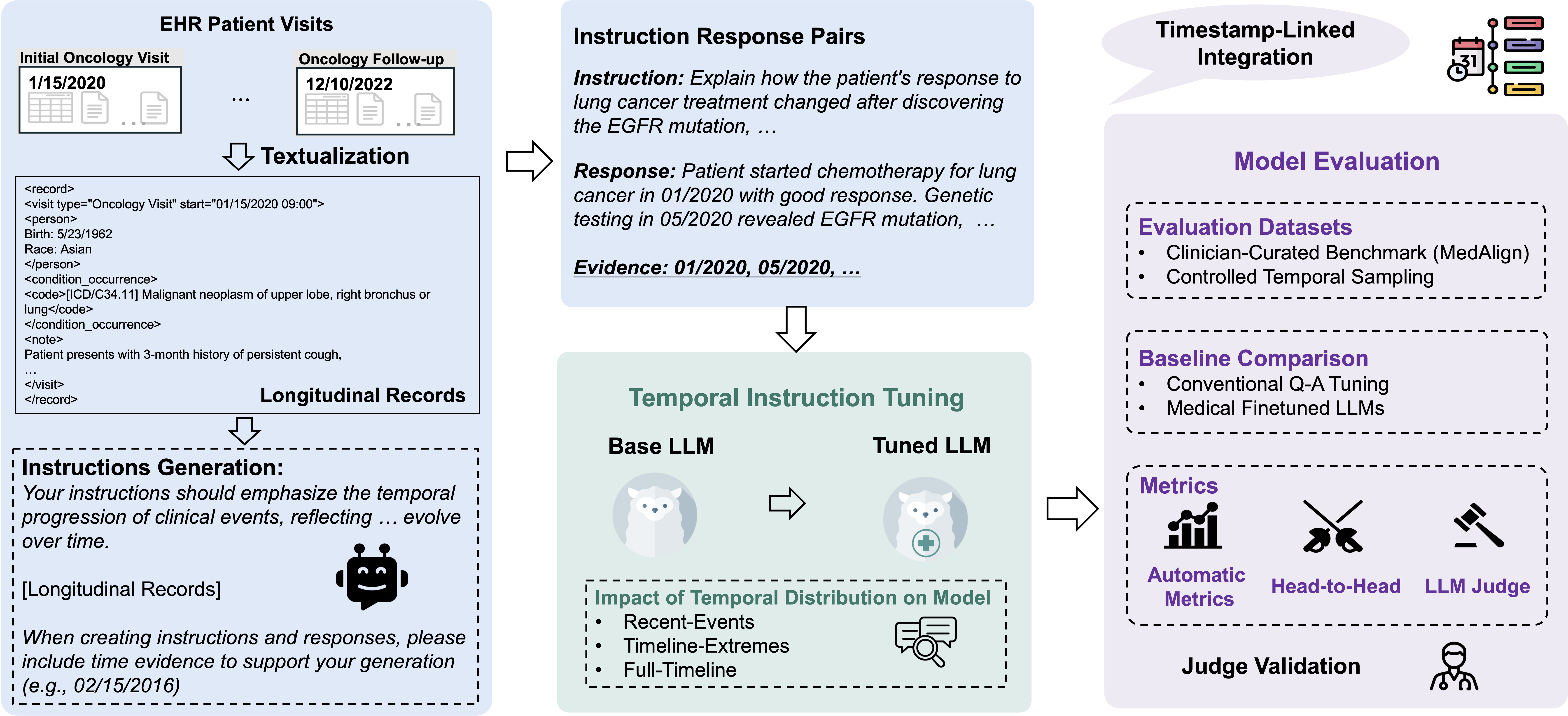
TIMER: Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records
Hejie Cui*, Alyssa Unell*, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, Nigam H. Shah (* equal contribution)
npj Digital Medicine (5-Year Impact Factor: 17.0) 2025
Electronic health records (EHRs) contain rich longitudinal information essential for clinical decision-making, yet large language models (LLMs) struggle to reason across patient timelines. We introduce TIMER (Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records), a method to improve LLMs' temporal reasoning over multi-visit EHRs through temporal instruction modeling and evaluation.
TIMER: Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records
Hejie Cui*, Alyssa Unell*, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, Nigam H. Shah (* equal contribution)
npj Digital Medicine (5-Year Impact Factor: 17.0) 2025
Electronic health records (EHRs) contain rich longitudinal information essential for clinical decision-making, yet large language models (LLMs) struggle to reason across patient timelines. We introduce TIMER (Temporal Instruction Modeling and Evaluation for Longitudinal Clinical Records), a method to improve LLMs' temporal reasoning over multi-visit EHRs through temporal instruction modeling and evaluation.
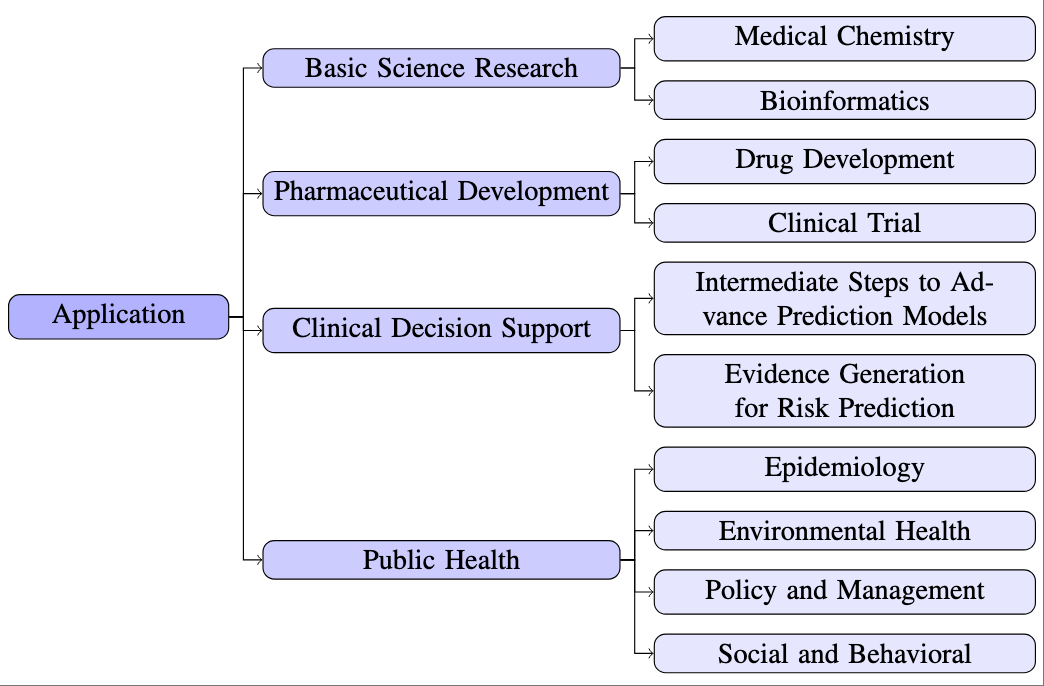
A Review on Knowledge Graphs for Healthcare: Resources, Applications, and Promises
Hejie Cui*, Jiaying Lu*, Ran Xu*, Shiyu Wang, Wenjing Ma, Yue Yu, Shaojun Yu, Xuan Kan, Chen Ling, Liang Zhao, Zhaohui S. Qin, Joyce C. Ho, Tianfan Fu, Jing Ma, Mengdi Huai, Fei Wang, Carl Yang (* equal contribution)
Journal of Biomedical Informatics (JBI) (5-Year Impact Factor: 7.7) 2025
Objective: This comprehensive review aims to provide an overview of the current state of Healthcare Knowledge Graphs (HKGs), including their construction, utilization models, and applications across various healthcare and biomedical research domains.
A Review on Knowledge Graphs for Healthcare: Resources, Applications, and Promises
Hejie Cui*, Jiaying Lu*, Ran Xu*, Shiyu Wang, Wenjing Ma, Yue Yu, Shaojun Yu, Xuan Kan, Chen Ling, Liang Zhao, Zhaohui S. Qin, Joyce C. Ho, Tianfan Fu, Jing Ma, Mengdi Huai, Fei Wang, Carl Yang (* equal contribution)
Journal of Biomedical Informatics (JBI) (5-Year Impact Factor: 7.7) 2025
Objective: This comprehensive review aims to provide an overview of the current state of Healthcare Knowledge Graphs (HKGs), including their construction, utilization models, and applications across various healthcare and biomedical research domains.
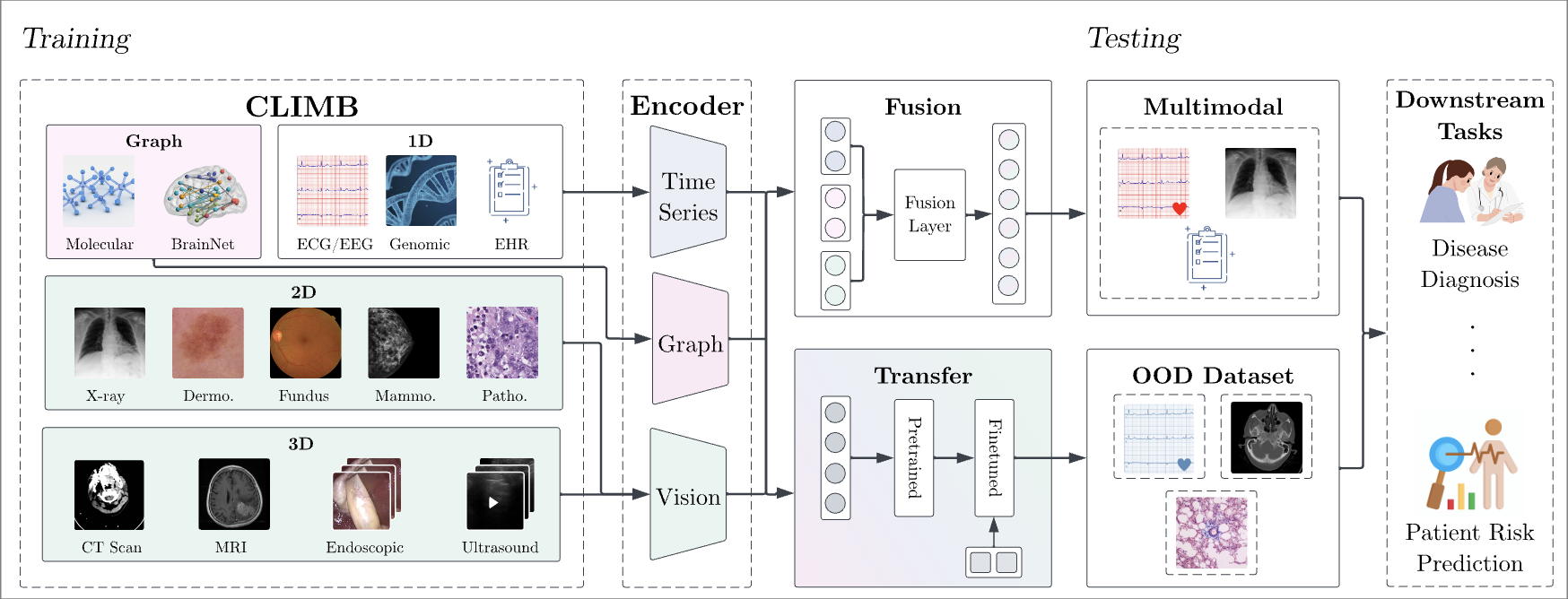
CLIMB: Data Foundations for Large Scale Multimodal Clinical Foundation Models
Wei Dai, Peilin Chen, Malinda Lu, Daniel Li, Haowen Wei, Hejie Cui, Paul Pu Liang
The International Conference on Machine Learning (ICML) 2025
Recent advances in clinical AI have enabled remarkable progress across many clinical domains. However, existing benchmarks and models are primarily limited to a small set of modalities and tasks, which hinders the development of large-scale multimodal methods that can make holistic assessments of patient health and well-being.
CLIMB: Data Foundations for Large Scale Multimodal Clinical Foundation Models
Wei Dai, Peilin Chen, Malinda Lu, Daniel Li, Haowen Wei, Hejie Cui, Paul Pu Liang
The International Conference on Machine Learning (ICML) 2025
Recent advances in clinical AI have enabled remarkable progress across many clinical domains. However, existing benchmarks and models are primarily limited to a small set of modalities and tasks, which hinders the development of large-scale multimodal methods that can make holistic assessments of patient health and well-being.
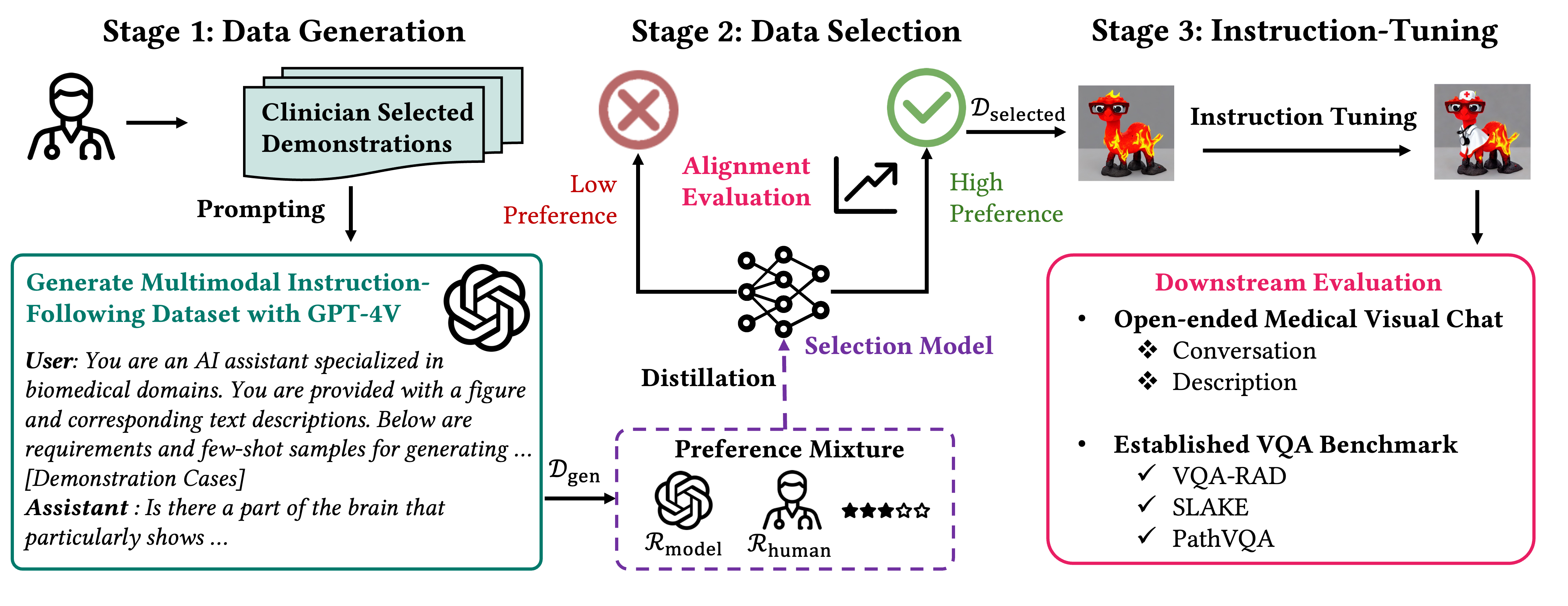
Biomedical Visual Instruction Tuning with Clinician Preference Alignment
Hejie Cui*, Lingjun Mao*, Xin Liang, Jieyu Zhang, Hui Ren, Quanzheng Li, Xiang Li, Carl Yang (* equal contribution)
The Conference on Neural Information Processing Systems (NeurIPS) 2024
Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets.
Biomedical Visual Instruction Tuning with Clinician Preference Alignment
Hejie Cui*, Lingjun Mao*, Xin Liang, Jieyu Zhang, Hui Ren, Quanzheng Li, Xiang Li, Carl Yang (* equal contribution)
The Conference on Neural Information Processing Systems (NeurIPS) 2024
Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets.
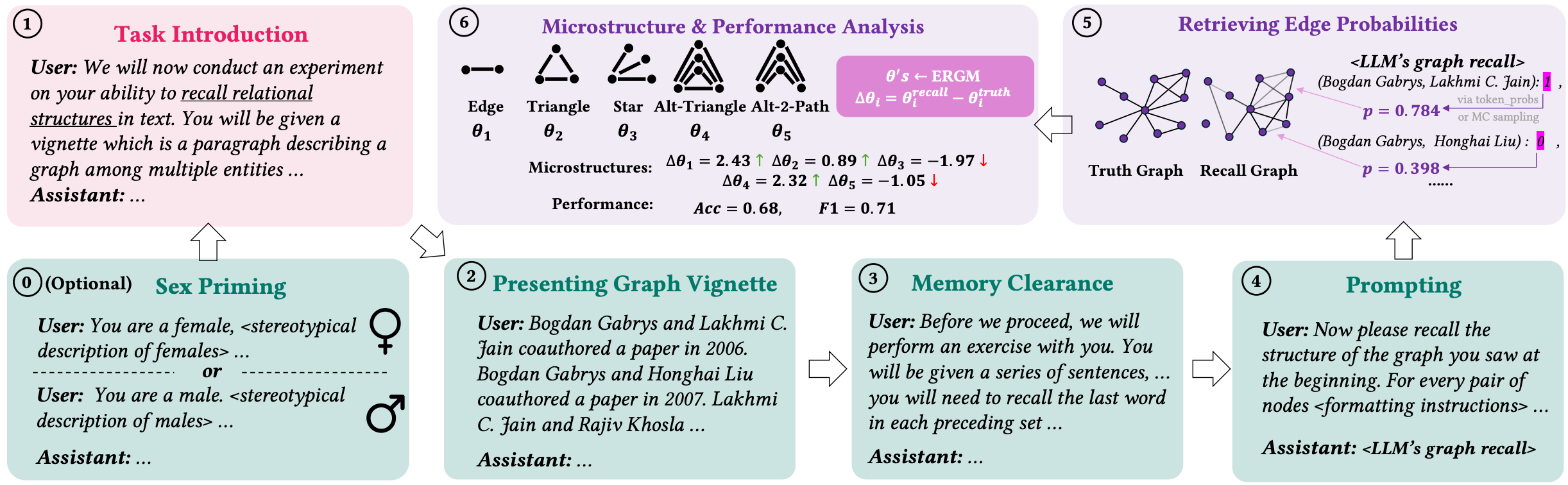
Microstructures and Accuracy of Graph Recall by Large Language Models
Yanbang Wang, Hejie Cui, Jon Kleinberg
The Conference on Neural Information Processing Systems (NeurIPS) 2024 IC2S2 Oral
Graphs data is crucial for many applications, and much of it exists in the relations described in textual format. As a result, being able to accurately recall and encode a graph described in earlier text is a basic yet pivotal ability that LLMs need to demonstrate if they are to perform reasoning tasks that involve graph-structured information.
Microstructures and Accuracy of Graph Recall by Large Language Models
Yanbang Wang, Hejie Cui, Jon Kleinberg
The Conference on Neural Information Processing Systems (NeurIPS) 2024 IC2S2 Oral
Graphs data is crucial for many applications, and much of it exists in the relations described in textual format. As a result, being able to accurately recall and encode a graph described in earlier text is a basic yet pivotal ability that LLMs need to demonstrate if they are to perform reasoning tasks that involve graph-structured information.
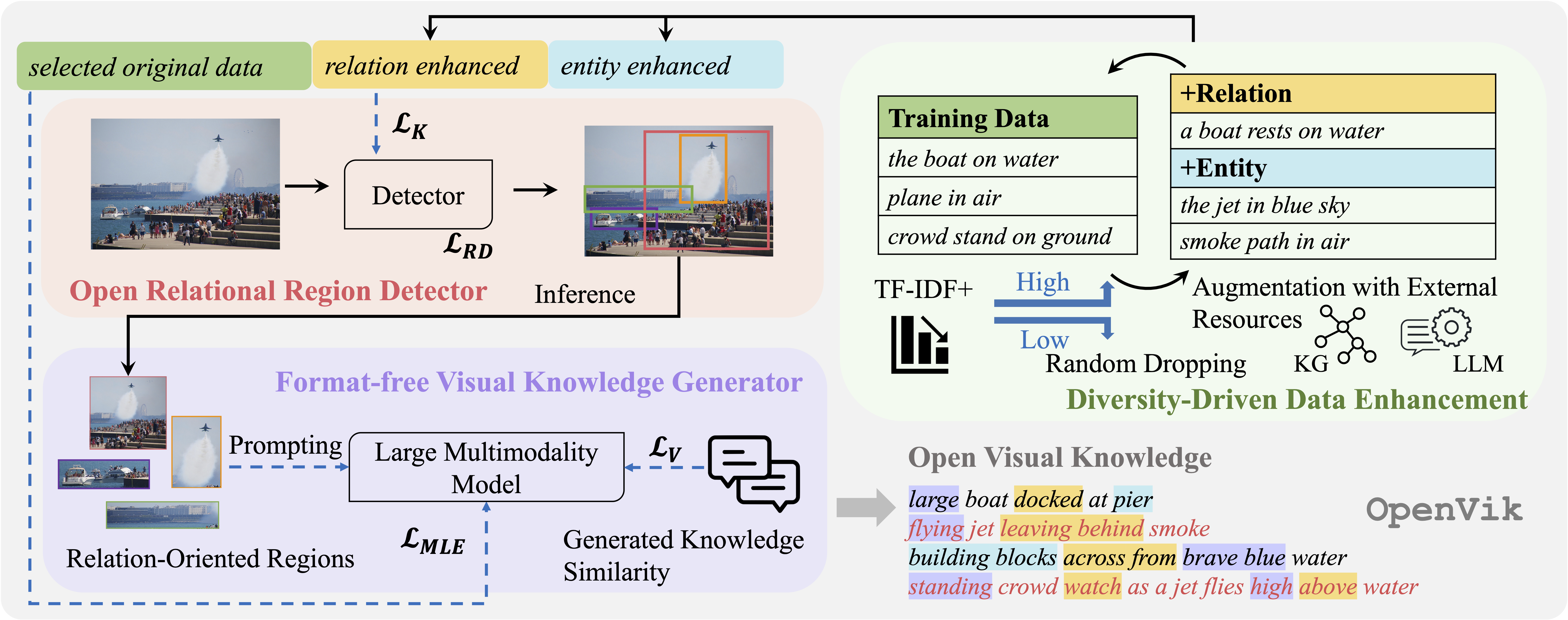
Open Visual Knowledge Extraction via Relation-Oriented Multimodality Model Prompting
Hejie Cui*, Xinyu Fang*, Zihan Zhang, Ran Xu, Xuan Kan, Xin Liu, Manling Li, Yangqiu Song, Carl Yang (* equal contribution)
The Conference on Neural Information Processing Systems (NeurIPS) 2023
Images contain rich relational knowledge that can help machines understand the world. Existing methods on visual knowledge extraction often rely on the pre-defined format (e.g., sub-verb-obj tuples) or vocabulary (e.g., relation types), restricting the expressiveness of the extracted knowledge. In this work, we take a first exploration to a new paradigm of open visual knowledge extraction.
Open Visual Knowledge Extraction via Relation-Oriented Multimodality Model Prompting
Hejie Cui*, Xinyu Fang*, Zihan Zhang, Ran Xu, Xuan Kan, Xin Liu, Manling Li, Yangqiu Song, Carl Yang (* equal contribution)
The Conference on Neural Information Processing Systems (NeurIPS) 2023
Images contain rich relational knowledge that can help machines understand the world. Existing methods on visual knowledge extraction often rely on the pre-defined format (e.g., sub-verb-obj tuples) or vocabulary (e.g., relation types), restricting the expressiveness of the extracted knowledge. In this work, we take a first exploration to a new paradigm of open visual knowledge extraction.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Hejie Cui, Rongmei Lin, Nasser Zalmout, Chenwei Zhang, Jingbo Shang, Carl Yang, Xian Li
Annual Meeting of the Association for Computational Linguistics (ACL-Findings) 2023
Attribute value extraction, as a fundamental task in e-Commerce services, has been extensively studied and formulated as text-based extraction. However, many attributes can benefit from image-based extraction, like the product color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Hejie Cui, Rongmei Lin, Nasser Zalmout, Chenwei Zhang, Jingbo Shang, Carl Yang, Xian Li
Annual Meeting of the Association for Computational Linguistics (ACL-Findings) 2023
Attribute value extraction, as a fundamental task in e-Commerce services, has been extensively studied and formulated as text-based extraction. However, many attributes can benefit from image-based extraction, like the product color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty.

BrainGB: A Benchmark for Brain Network Analysis with Graph Neural Networks
Hejie Cui, Wei Dai, Yanqiao Zhu, Xuan Kan, Antonio Aodong Chen Gu, Joshua Lukemire, Liang Zhan, Lifang He, Ying Guo, Carl Yang
IEEE Transactions on Medical Imaging (5-Year Impact Factor: 12.3) 2022
Mapping the connectome of the human brain using structural or functional connectivity has become one of the most pervasive paradigms for neuroimaging analysis. Recently, Graph Neural Networks (GNNs) motivated from geometric deep learning have attracted broad interest due to their established power for modeling complex networked data.
BrainGB: A Benchmark for Brain Network Analysis with Graph Neural Networks
Hejie Cui, Wei Dai, Yanqiao Zhu, Xuan Kan, Antonio Aodong Chen Gu, Joshua Lukemire, Liang Zhan, Lifang He, Ying Guo, Carl Yang
IEEE Transactions on Medical Imaging (5-Year Impact Factor: 12.3) 2022
Mapping the connectome of the human brain using structural or functional connectivity has become one of the most pervasive paradigms for neuroimaging analysis. Recently, Graph Neural Networks (GNNs) motivated from geometric deep learning have attracted broad interest due to their established power for modeling complex networked data.
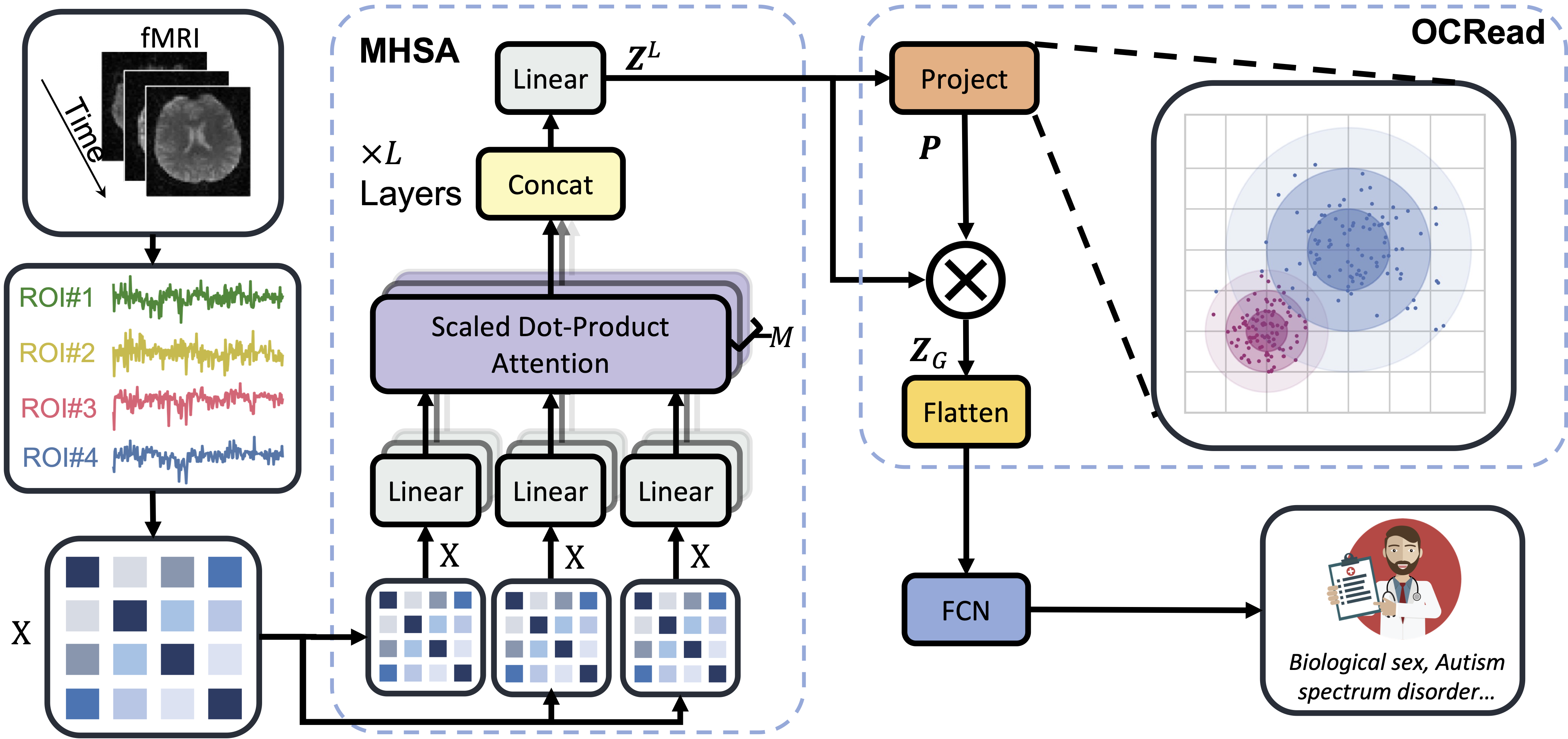
Brain Network Transformer
Xuan Kan, Wei Dai, Hejie Cui, Zilong Zhang, Ying Guo, Carl Yang
The Conference on Neural Information Processing Systems (NeurIPS) 2022 Spotlight
Human brains are commonly modeled as networks of Regions of Interest (ROIs) and their connections for the understanding of brain functions and mental disorders. Recently, Transformer-based models have been studied over different types of data, including graphs, shown to bring performance gains widely. In this work, we study Transformer-based models for brain network analysis.
Brain Network Transformer
Xuan Kan, Wei Dai, Hejie Cui, Zilong Zhang, Ying Guo, Carl Yang
The Conference on Neural Information Processing Systems (NeurIPS) 2022 Spotlight
Human brains are commonly modeled as networks of Regions of Interest (ROIs) and their connections for the understanding of brain functions and mental disorders. Recently, Transformer-based models have been studied over different types of data, including graphs, shown to bring performance gains widely. In this work, we study Transformer-based models for brain network analysis.

On Positional and Structural Node Features for Graph Neural Networks on Non-attributed Graphs
Hejie Cui, Zijie Lu, Pan Li, Carl Yang
The ACM International Conference on Information and Knowledge Management (CIKM) 2022 Most Influential CIKM Paper of 2022
Graph neural networks (GNNs) have been widely used in various graph-related problems such as node classification and graph classification, where the superior performance is mainly established when natural node features are available. However, it is not well understood how GNNs work without natural node features, especially regarding the various ways to construct artificial ones.
On Positional and Structural Node Features for Graph Neural Networks on Non-attributed Graphs
Hejie Cui, Zijie Lu, Pan Li, Carl Yang
The ACM International Conference on Information and Knowledge Management (CIKM) 2022 Most Influential CIKM Paper of 2022
Graph neural networks (GNNs) have been widely used in various graph-related problems such as node classification and graph classification, where the superior performance is mainly established when natural node features are available. However, it is not well understood how GNNs work without natural node features, especially regarding the various ways to construct artificial ones.